Kernel Execution
Run custom Python code in isolated Docker containers with full access to your flow's data.
Not in Flowfile Lite
Kernel execution requires Docker and the full desktop/server build. The browser-only Flowfile Lite edition cannot run kernels — use the Polars Code node for in-browser Python/Polars logic.
Beta Feature
Kernel execution is currently in beta. The core functionality is working, but some features are still under active development and optimization. See Known Limitations for details.
Kernels provide a sandboxed execution environment for Python Script nodes. Each kernel runs inside its own Docker container with configurable resources (CPU, memory, GPU), persistent namespaces across executions, and access to the flowfile_ctx API for reading inputs, writing outputs, and managing artifacts.
Renamed from flowfile
The kernel-context global was previously called flowfile. It has been renamed to flowfile_ctx to avoid colliding with the flowfile PyPI package, which you may want to import inside a cell. The old name still works (it forwards to flowfile_ctx and emits a DeprecationWarning on first use) but will be removed in a future release.
Prerequisites
- Docker must be installed and running on the host machine
- The flowfile-kernel Docker image must be built:
docker compose build flowfile-kernel
Desktop App
When running Flowfile as a desktop application, Docker must be available on your local machine. Verify with docker info.
Kernel Manager
The Kernel Manager is the central dashboard for creating, starting, stopping, and monitoring kernels. Open it from the sidebar menu.
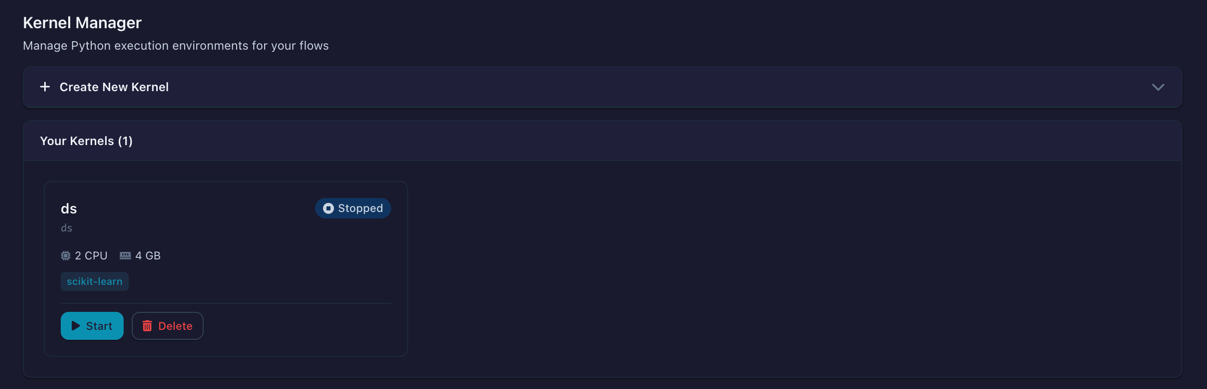
The Kernel Manager showing configured kernels with status, resource usage, and actions
When Docker is not running or the kernel image has not been built, a status banner appears at the top of the page with instructions on how to resolve the issue.

Warning banner shown when Docker is unavailable or the kernel image is missing
Creating a Kernel
- In the Kernel Manager, click Create Kernel to expand the creation form
- Fill in the configuration fields:
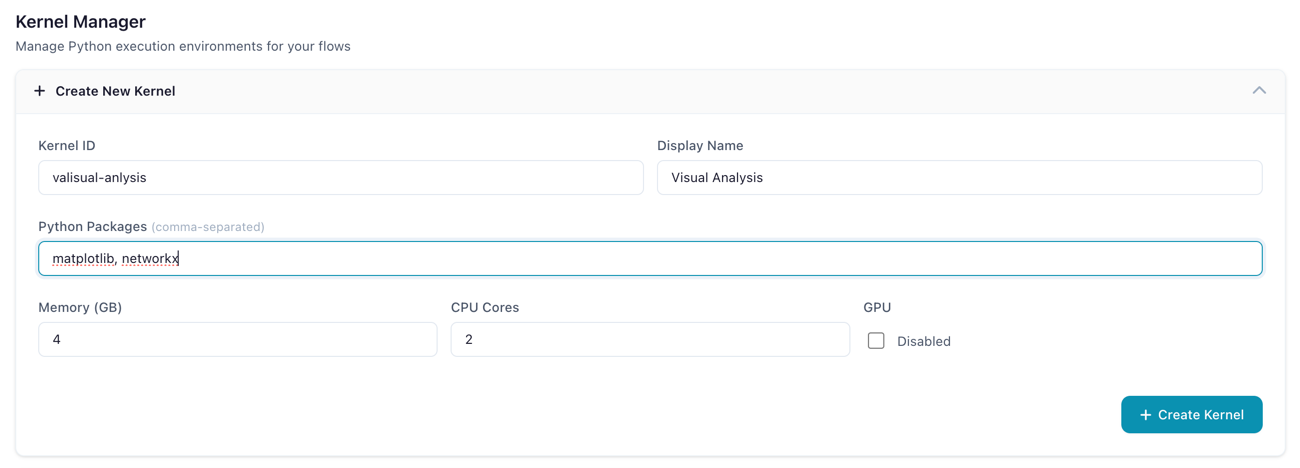
The kernel creation form with resource configuration options
| Setting | Description | Default |
|---|---|---|
| Kernel ID | Unique identifier (alphanumeric) | — |
| Name | A human-readable display label | — |
| Packages | Comma-separated pip packages to install at startup | (none) |
| Memory (GB) | Maximum memory the container can use (0.5–64 GB) | 2 |
| CPU Cores | Number of CPU cores allocated (0.5–32) | 2 |
| GPU | Enable GPU passthrough (requires NVIDIA Docker) | false |
- Click Create Kernel to save the configuration
- Click Start on the kernel card to launch the container
Kernel Cards
Each kernel is displayed as a card showing its current state, resource allocation, and live memory usage.
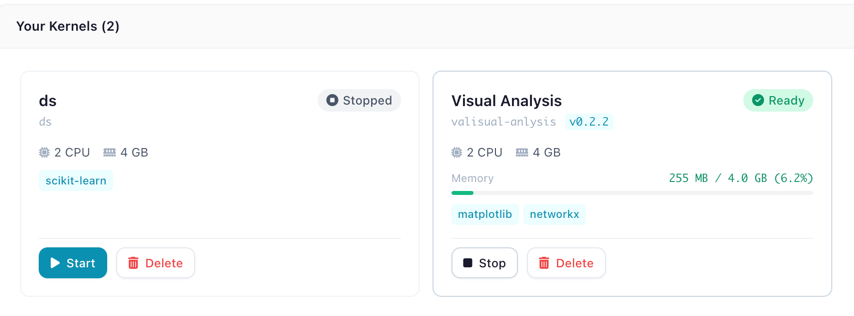
A kernel card showing status badge, CPU/memory allocation, installed packages, and memory usage bar
The status badge indicates the kernel's current state:
| Status | Badge | Meaning |
|---|---|---|
| Stopped | Gray | Container is not running |
| Starting | Blue (animated) | Container is initializing |
| Ready | Green | Idle and ready for execution |
| Executing | Orange (animated) | Currently running code |
| Error | Red | Failed — check error message on the card |
The memory usage bar shows real-time consumption, color-coded green (normal), orange (warning, >80%), or red (critical, >95%).
Python Script Node
Add a Python Script node to your flow to write and execute Python code in a kernel.
Selecting a Kernel
In the node settings panel, the kernel dropdown shows all available kernels with their current state.
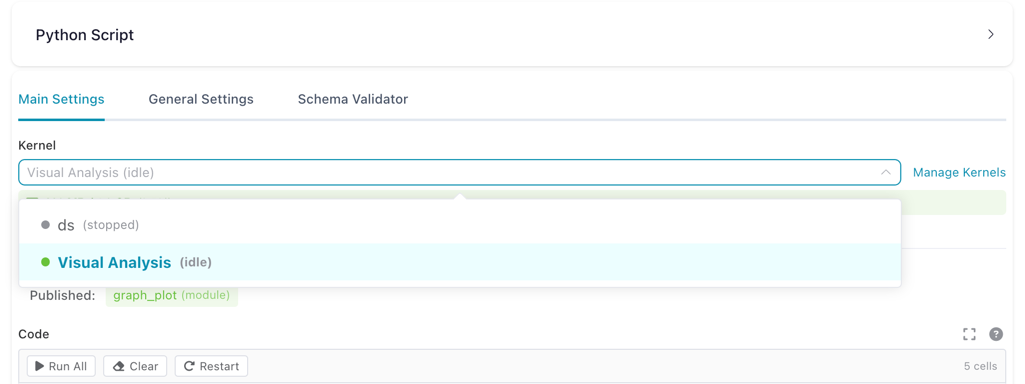
Kernel dropdown in the Python Script node settings, showing available kernels and their state
Kernel Required
A running kernel is required to execute Python code. If no kernel is selected or the selected kernel is stopped, a warning message appears with instructions.
Notebook Editor
The code editor uses a Jupyter-style notebook interface with multiple cells. Each cell can be executed independently.
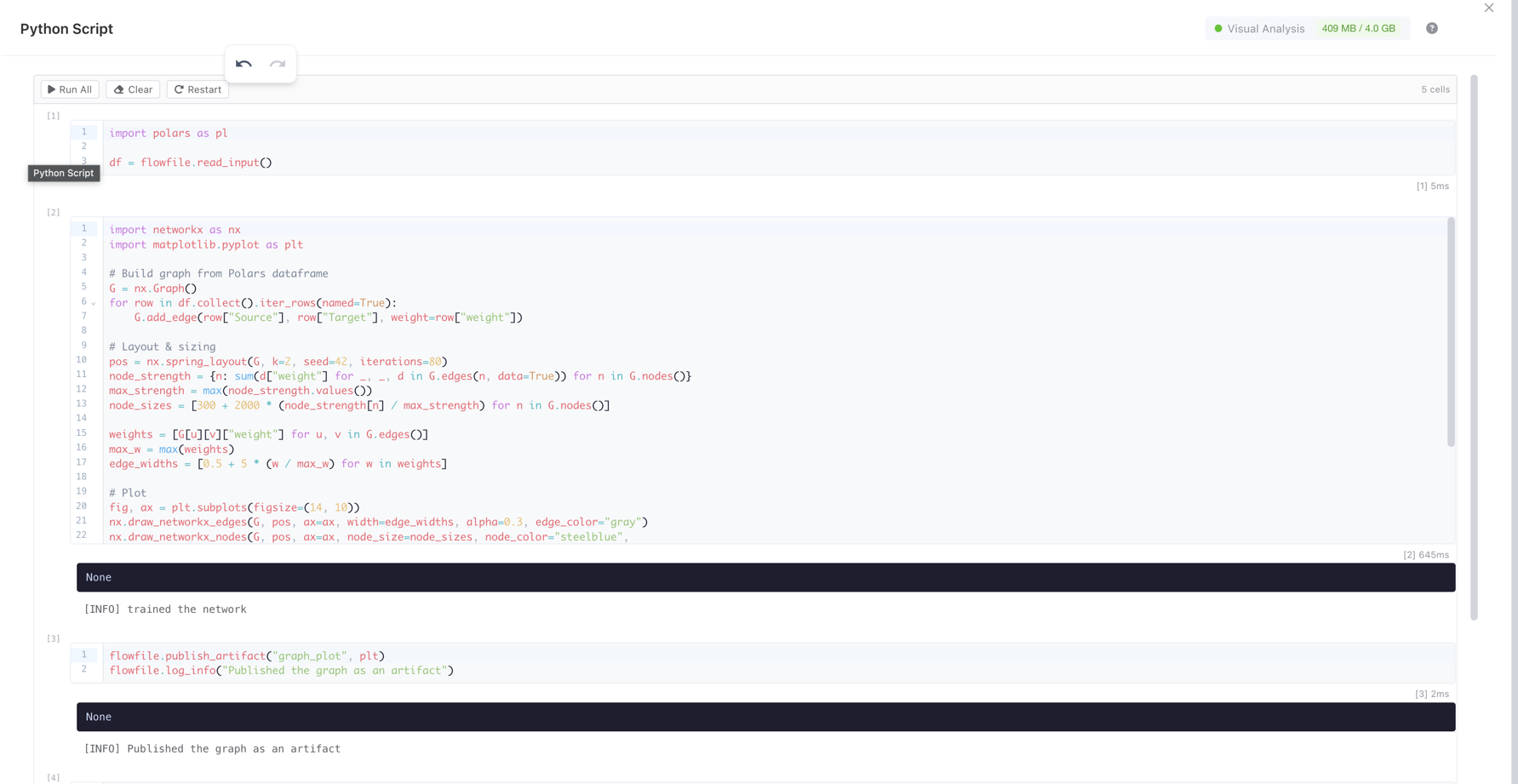
The notebook editor showing multiple code cells with execution counters, a toolbar, and output
Toolbar actions:
| Button | Description |
|---|---|
| Run All | Execute all cells in order |
| Clear | Erase all cell outputs |
| Restart | Clear all kernel variables for this flow |
Cell actions (visible on hover):
| Action | Shortcut | Description |
|---|---|---|
| Run cell | Shift+Enter |
Execute the cell |
| Run and advance | Cmd/Ctrl+Enter |
Execute and move to next cell |
| Move up/down | — | Reorder cells |
| Delete | — | Remove the cell |
Cell Output
After executing a cell, the output area shows results, stdout, and any errors.
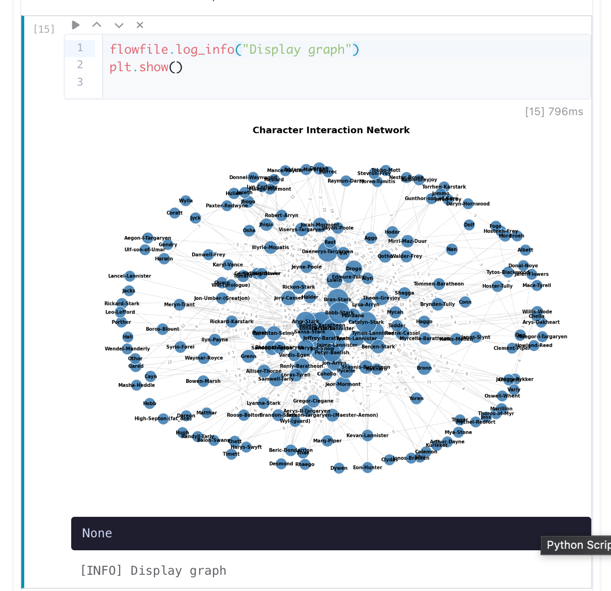
Cell output showing a rendered matplotlib chart, execution time, and stdout
Output types rendered:
- Tables — Polars DataFrames/LazyFrames as interactive sortable tables
- Charts — matplotlib and plotly figures rendered inline
- Images — PIL images displayed as PNG
- HTML — rendered in a sandboxed iframe
- Text — plain text from
print()statements orflowfile_ctx.display() - Errors — tracebacks displayed in a red block
Expanded Editor
Click Expand Editor to open a fullscreen code editing view. The expanded editor shows the kernel status and memory usage in the header bar.
Artifacts Panel
The node settings panel shows artifacts available from upstream nodes and artifacts published by the current node.
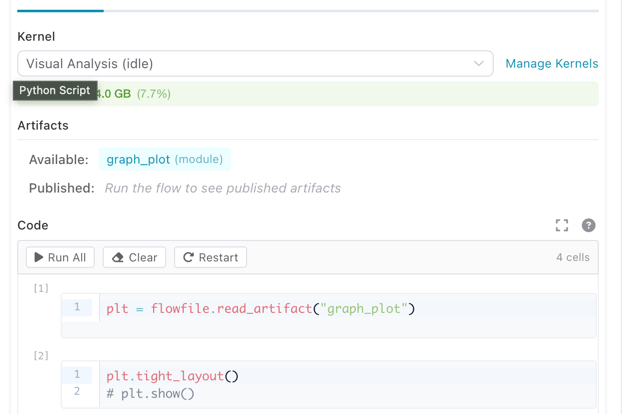
Artifacts panel showing available upstream artifacts and published artifacts for the current node
API Reference
Click the ? button in the code editor header to open the built-in API reference.
Writing Code
Inside a Python Script node connected to a kernel, you write standard Python code. The flowfile module is available automatically — no imports needed.
Reading Input Data
When multiple nodes are connected to a Python Script node, each input gets a name derived from the source node's node reference. These names are visible as edge labels on the canvas, so you can see at a glance which data flows into which input.
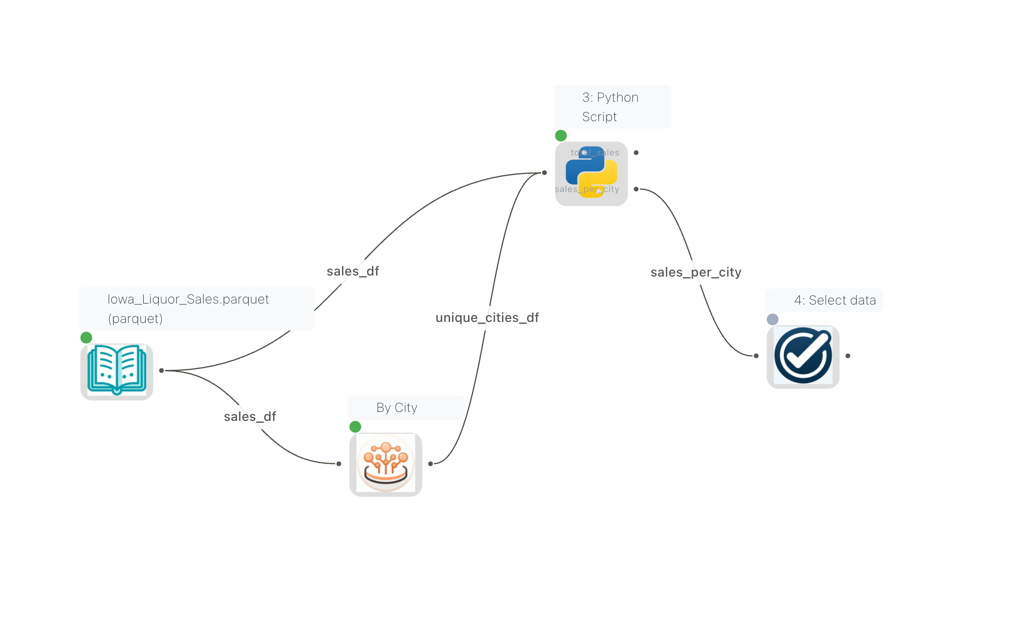
Edge labels on the canvas showing the names of each connection into the Python Script node
The Python Script node settings panel displays an Available Inputs section that lists all connected inputs by name and source node type. Use these names with flowfile_ctx.read_input("name") to read a specific input.

The Available Inputs panel showing input names and their source node types
# Read the main input as a Polars LazyFrame
df = flowfile_ctx.read_input()
# Read a named input (when multiple inputs are connected)
orders = flowfile_ctx.read_input("orders")
customers = flowfile_ctx.read_input("customers")
# Read all inputs at once
all_inputs = flowfile_ctx.read_inputs()
# Returns: {"main": [LazyFrame, ...], "orders": [LazyFrame, ...]}
Setting input names
Input names come from the node reference of each source node. You can set or change a node's reference in its settings panel. If no reference is set, the default name is df_{node_id}. Names must be lowercase and can only contain letters, digits, and underscores.
Showing connection names on the canvas
To display connection names on the canvas, enable Show edge labels in the Flow Settings.
Writing Output Data
A Python Script node can publish multiple named outputs, each flowing to a different downstream node. To set this up:
- In the node settings panel, add output names under Output Names (e.g.
total_sales,sales_per_city) - In your code, use
flowfile_ctx.publish_output(df, "name")to publish data to each named output
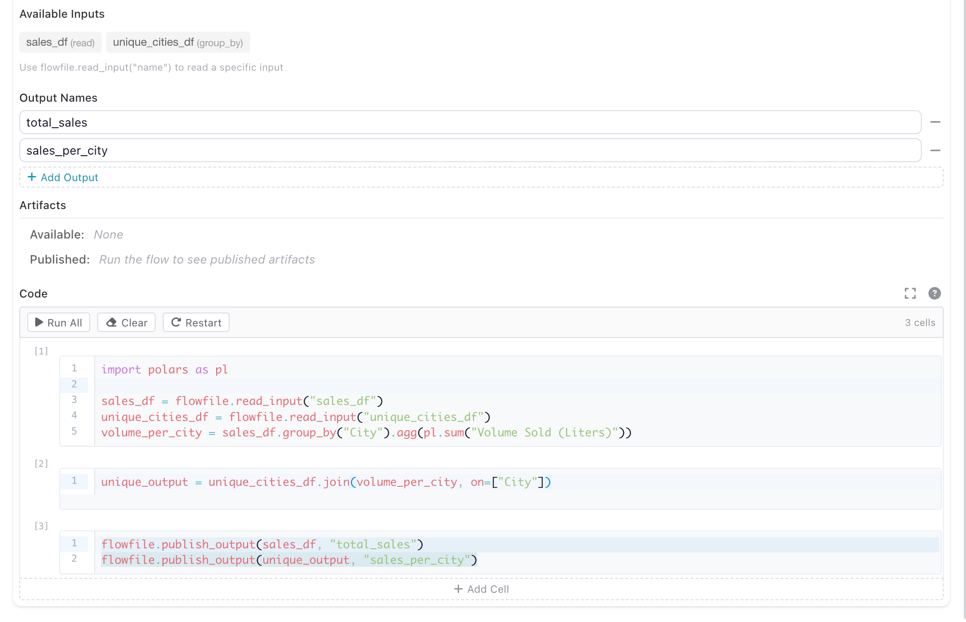
The Python Script node settings showing two named outputs (total_sales and sales_per_city) and the code that publishes to them
# Publish a single (default) output
result = df.filter(pl.col("amount") > 100).select("id", "amount", "date")
flowfile_ctx.publish_output(result)
# Publish multiple named outputs
flowfile_ctx.publish_output(sales_df, "total_sales")
flowfile_ctx.publish_output(unique_output, "sales_per_city")
Both pl.LazyFrame and pl.DataFrame are accepted by publish_output.
Displaying Results
Use flowfile_ctx.display() to render rich output in the node's output panel:
# Display a matplotlib chart
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(["A", "B", "C"], [10, 20, 15])
ax.set_title("Sales by Category")
flowfile_ctx.display(fig, title="Sales Chart")
Supported display types:
| Object Type | Rendering |
|---|---|
polars.DataFrame / polars.LazyFrame |
Interactive sortable table |
matplotlib.figure.Figure |
PNG image |
plotly.graph_objects.Figure |
Interactive HTML |
PIL.Image.Image |
PNG image |
HTML string (e.g. "<b>hello</b>") |
Rendered HTML |
| Any other object | Plain text via str() |
A Polars DataFrame or LazyFrame renders as an interactive, sortable table
(LazyFrames are head-collected). Up to 10,000 rows are shown by default — pass
max_rows= to change the cap:
df = flowfile_ctx.read_input().collect()
flowfile_ctx.display(df) # interactive table
flowfile_ctx.display(df, max_rows=500) # smaller cap
For ad-hoc visual exploration of a frame, use flowfile_ctx.explore() — it opens
the full Graphic Walker explorer (a data grid plus a drag-to-chart visualization
builder) inline:
flowfile_ctx.explore(df)
Interactive mode
In cell-execution mode, the last expression in your code is automatically displayed — similar to Jupyter notebooks. A bare df shows its repr (what the object is); call flowfile_ctx.display(df) for the interactive table or flowfile_ctx.explore(df) for the explorer.
Logging
Send real-time log messages to the flow viewer:
flowfile_ctx.log("Processing started")
flowfile_ctx.log_info("Loaded 1,234 rows")
flowfile_ctx.log_warning("Column 'price' has 5 null values")
flowfile_ctx.log_error("Failed to parse date column")
Artifacts
Artifacts let you persist Python objects (models, arrays, DataFrames) across executions within the same flow. They are scoped to the flow that created them.
Local Artifacts (Flow-scoped)
# Save a trained model
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier().fit(X_train, y_train)
flowfile_ctx.publish_artifact("rf_model", model)
# In a later execution or different node in the same flow:
model = flowfile_ctx.read_artifact("rf_model")
predictions = model.predict(X_test)
# List all artifacts in this flow
artifacts = flowfile_ctx.list_artifacts()
for a in artifacts:
print(f"{a.name} (node {a.node_id})")
# Delete an artifact
flowfile_ctx.delete_artifact("rf_model")
Artifacts are automatically serialized using the best format for the object type:
| Object Type | Format |
|---|---|
| Polars / Pandas DataFrame | Parquet |
| scikit-learn, NumPy, XGBoost, LightGBM | Joblib |
| Everything else | Cloudpickle |
Global Artifacts (Catalog)
Global artifacts are stored in the Flowfile catalog and persist beyond the current flow. They can be retrieved from any flow or session.
# Publish to the global catalog
artifact_id = flowfile_ctx.publish_global(
"sales_model_v2",
model,
description="Random Forest trained on Q4 data",
tags=["ml", "classification"],
)
# Retrieve from the global catalog
model = flowfile_ctx.get_global("sales_model_v2")
# Get a specific version
model_v1 = flowfile_ctx.get_global("sales_model_v2", version=1)
# List all global artifacts
artifacts = flowfile_ctx.list_global_artifacts(tags=["ml"])
for a in artifacts:
print(f"{a.name} v{a.version} — {a.python_type}")
# Delete a global artifact
flowfile_ctx.delete_global_artifact("sales_model_v2")
Registered Flows Required
publish_global requires the flow to be registered in the catalog. It is not available in interactive (cell) mode.
Artifact Persistence
Local artifacts are automatically saved to disk and recovered if the kernel restarts — no configuration needed.
Catalog Tables
Kernel cells can read and write Delta-format catalog tables directly, mirroring the flowfile_frame.read_catalog_table / write_catalog_table API. The kernel performs the Delta write locally (it has direct access to the catalog storage) and reports the resulting metadata to Core — Core never materialises the dataset.
The kernel exposes three typed handles — CatalogRef, SchemaRef, TableRef — for path-style navigation. The top-level read_catalog_table / write_catalog_table still accept plain strings for one-shot scripts.
import polars as pl
# Navigate the hierarchy
cat = flowfile_ctx.get_catalog("General") # CatalogRef
sch = cat.get_schema("default") # SchemaRef
orders = sch.get_table_ref("orders") # TableRef (may not exist yet)
# Shortcut from a catalog ref
orders = cat.get_table_ref(schema_name="default", table_name="orders")
# Or grab the seeded default schema directly
sch = flowfile_ctx.default_schema()
# Discover everything available
for cat in flowfile_ctx.list_catalogs():
print(cat.name)
for sch in cat.list_schemas():
for tbl in sch.list_tables():
print(f" {sch.name}.{tbl.name} ({tbl.row_count} rows)")
# Read via a ref — equivalent to flowfile_ctx.read_catalog_table(orders)
df = orders.read()
df_v3 = orders.read(delta_version=3) # time travel
# Write via the ref — creates the table if it doesn't exist yet
new_data = pl.DataFrame({"id": [1, 2, 3], "name": ["a", "b", "c"]})
orders = orders.write(new_data, write_mode="overwrite") # returns refreshed ref
# Per-mode writes
orders.write(new_data, write_mode="append")
orders.write(new_data, write_mode="upsert", merge_keys=["id"])
orders.write(new_data, write_mode="update", merge_keys=["id"])
orders.write(new_data.select("id"), write_mode="delete", merge_keys=["id"])
orders.write(new_data, write_mode="error") # raises if table already exists
# Schema-level convenience: same effect, no intermediate ref
sch.write_table(new_data, "customers", write_mode="overwrite")
sch.read_table("customers")
# String form still works for one-shot usage
lf = flowfile_ctx.read_catalog_table("orders") # default schema
lf = flowfile_ctx.read_catalog_table("orders", schema="sales")
flowfile_ctx.write_catalog_table(new_data, "customers", write_mode="overwrite")
write_mode |
Behaviour | Requires merge_keys |
|---|---|---|
overwrite |
Replace the table's data (Delta version increments). | No |
append |
Add rows; schema_mode="merge" so new columns are tolerated. | No |
upsert |
Insert new rows, update existing rows matched by merge keys. | Yes |
update |
Update only existing rows that match merge keys. | Yes |
delete |
Remove rows matching merge keys. | Yes |
error |
Fail if the table already exists. | No |
No virtual mode in the kernel
flowfile_frame.write_catalog_table also supports a "virtual" mode that backs a table by a registered flow. The kernel intentionally does not expose flow registration or virtual writes — author those flows from the visual editor or flowfile_frame instead.
Shared Files
Use flowfile_ctx.get_shared_location() to write files that are accessible across all Flowfile services and survive container restarts:
# Write a CSV to the shared directory
output_path = flowfile_ctx.get_shared_location("reports/monthly.csv")
df.collect().write_csv(output_path)
# The file is now accessible from other nodes and services
Using Kernels in the Node Designer
Custom nodes built with the Node Designer can also run on kernels. This lets you create reusable nodes that depend on third-party libraries (e.g. scikit-learn, XGBoost) or that need artifact support.
Enabling Kernel Mode
In the Node Designer, check Require Kernel Execution in the metadata section. This reveals a kernel selector and output name configuration.
The Node Designer with kernel execution enabled, showing the kernel dropdown and output names
When a user drops your kernel-enabled custom node into a flow, the node settings panel shows a kernel dropdown so they can choose which kernel runs it.
A kernel-enabled custom node in a flow with the kernel selector visible
What Changes
Your process method code stays the same — the self.settings_schema access pattern works identically. Behind the scenes, the Node Designer generates a self-contained kernel script that:
- Creates proxy classes replicating
self.settings_schema.section.component.value - Reads inputs via
flowfile_ctx.read_input() - Runs your process method body
- Publishes outputs via
flowfile_ctx.publish_output()for each named output
The full flowfile API (artifacts, display, logging) is available inside kernel-enabled custom nodes.
For details on building custom nodes, see Node Designer.
Known Limitations
Kernel execution is in beta. The following limitations are known and being worked on:
- Flow-to-code export — Python Script nodes that use kernel execution are not yet included in the Export to Python code generator. Kernel nodes will be skipped in the generated code.
- Artifact state visibility — There is currently no UI to browse or inspect the contents of stored artifacts. You can list artifacts via
flowfile_ctx.list_artifacts()in code, but there is no visual artifact explorer yet. - Python package versioning — Packages specified during kernel creation are installed via
pip installat container startup without version pinning. There is no lock file or reproducible environment mechanism yet. To pin versions, specify them explicitly in the packages field (e.g.scikit-learn==1.4.0, pandas==2.1.0).
flowfile API Reference
The following functions are available inside kernel code via the flowfile module:
Data I/O
| Function | Description |
|---|---|
read_input(name="main") |
Read input data as a pl.LazyFrame if more then one sources are provided. It attempts to concat all sources. |
read_inputs() |
Read all named inputs as dict[str, list[LazyFrame]] |
publish_output(df, name="main") |
Write a DataFrame/LazyFrame as output |
Local Artifacts
| Function | Description |
|---|---|
publish_artifact(name, obj) |
Store a Python object in the flow's artifact store |
read_artifact(name) |
Retrieve a stored artifact |
delete_artifact(name) |
Remove an artifact |
list_artifacts() |
List all artifacts in the current flow |
Global Artifacts
| Function | Description |
|---|---|
publish_global(name, obj, ...) |
Persist an object to the global catalog |
get_global(name, version=None) |
Retrieve from the global catalog |
list_global_artifacts(...) |
List available global artifacts |
delete_global_artifact(name, ...) |
Delete a global artifact |
Display & Logging
| Function | Description |
|---|---|
display(obj, title="") |
Render rich output (charts, images, HTML, text) |
log(message, level="INFO") |
Send a log message to the flow viewer |
log_info(message) |
Shortcut for log(message, "INFO") |
log_warning(message) |
Shortcut for log(message, "WARNING") |
log_error(message) |
Shortcut for log(message, "ERROR") |
Utilities
| Function | Description |
|---|---|
get_shared_location(filename) |
Get a path in the shared directory |
Related Documentation
- Node Designer — Create custom nodes with kernel support
- Building Flows — Using nodes in workflows
- Transform Nodes — Built-in transformation nodes
- Docker Deployment — Running Flowfile with Docker
- Kernel Architecture — Technical deep-dive for developers