Flowfile
An open-source data platform with a visual pipeline builder, AI assistant, data catalog, Delta Lake storage, scheduling, Kafka ingestion, sandboxed Python execution, and a Polars-compatible API — all in a single pip install.
An open-source data platform with a visual pipeline builder, AI assistant, data catalog, Delta Lake storage, scheduling, Kafka ingestion, sandboxed Python execution, and a Polars-compatible API — all in a single pip install.
A complete data platform — visual pipeline builder, catalog, scheduling, and more — powered by Polars
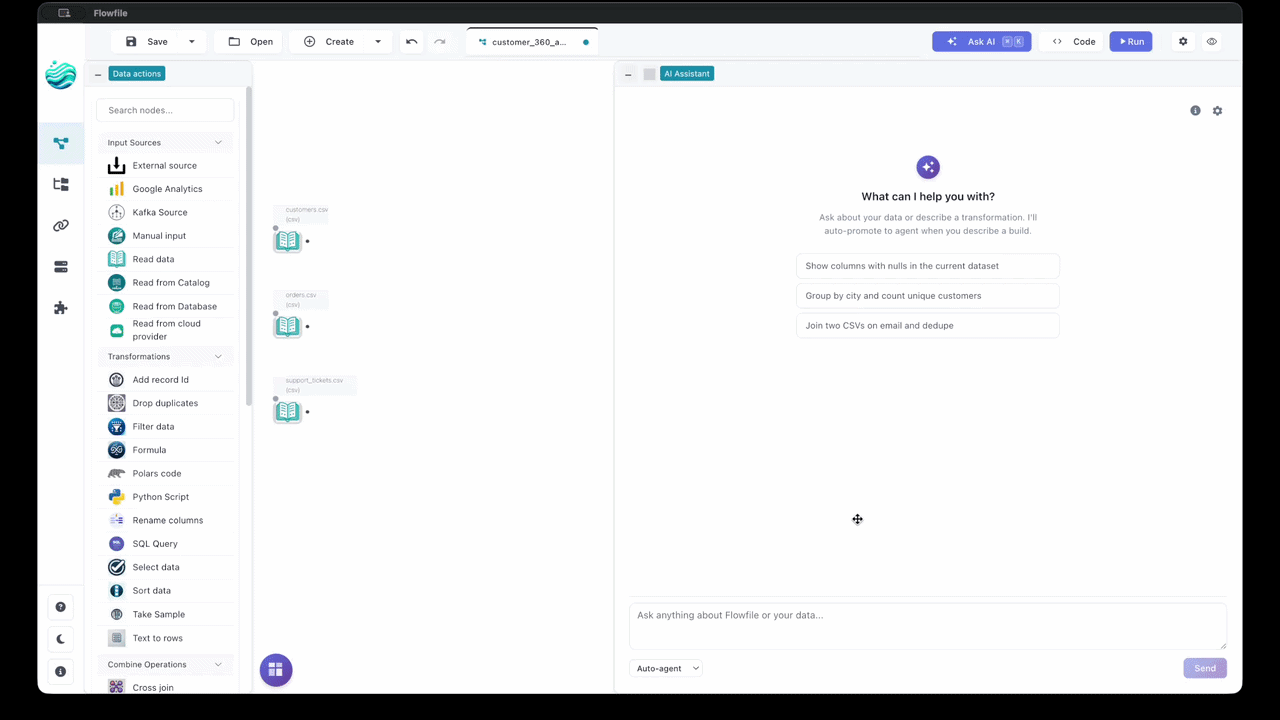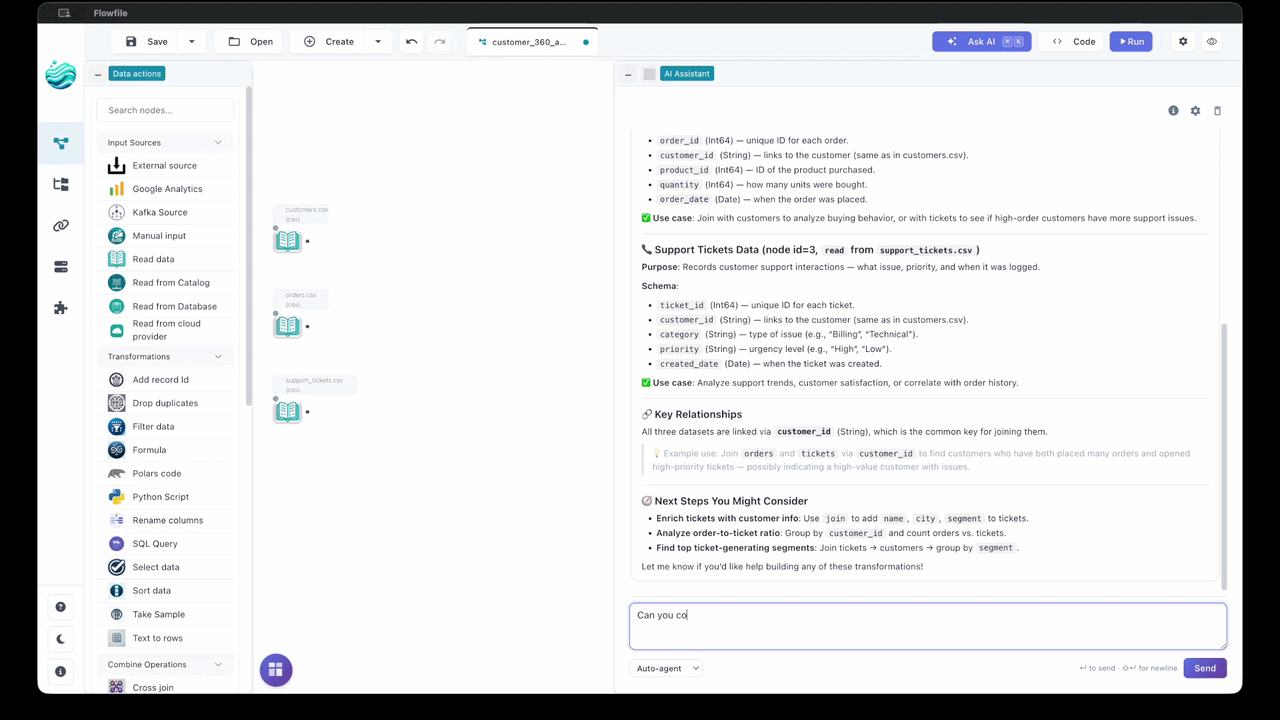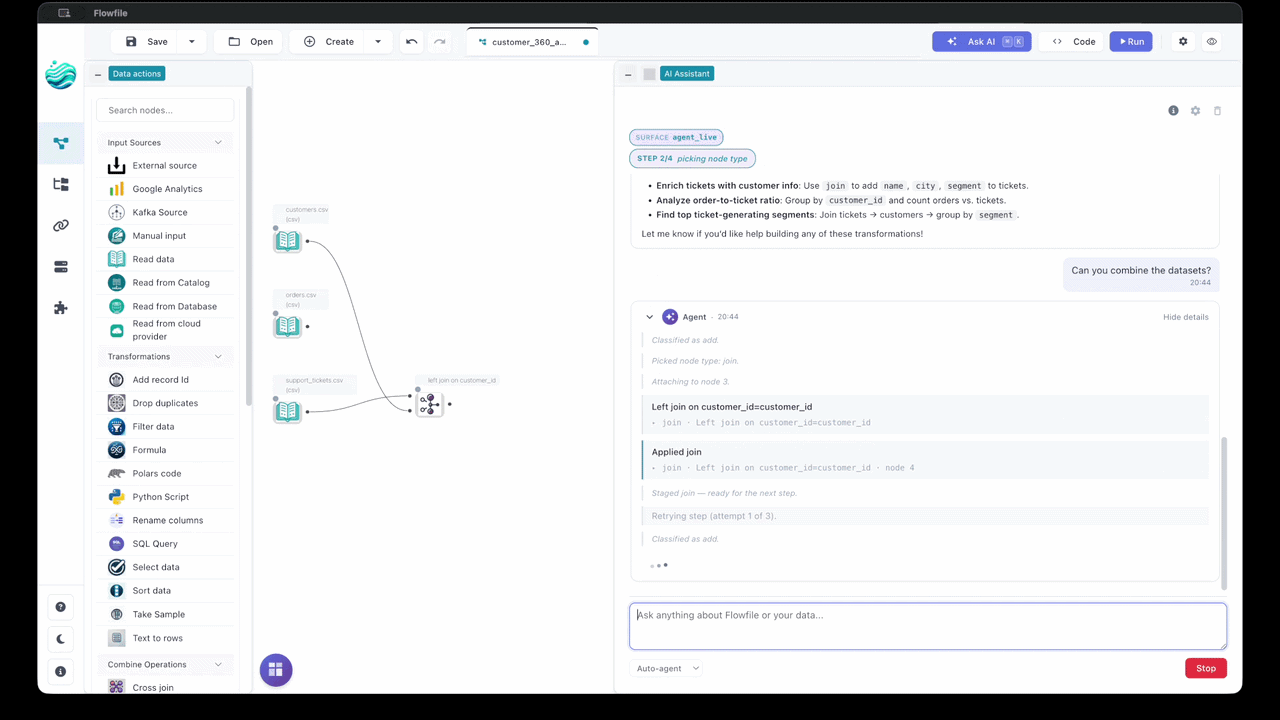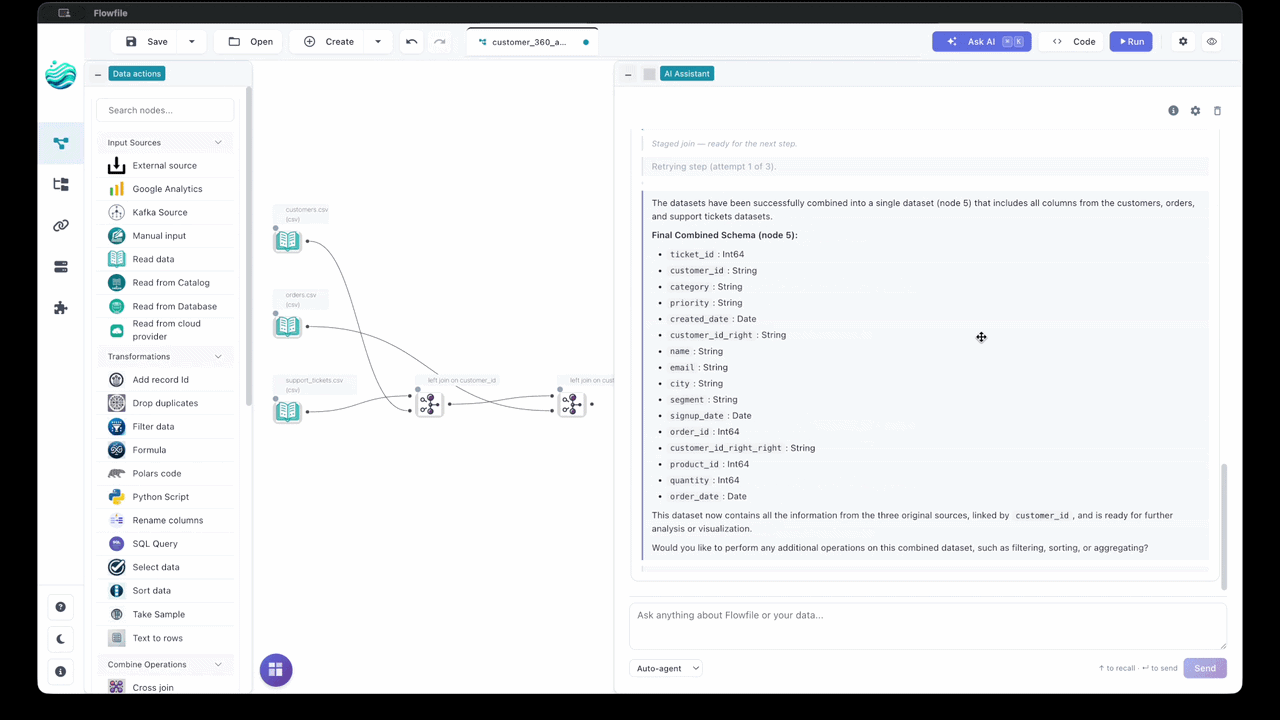
Build pipelines from natural-language prompts, ask questions about a flow you didn't write, and turn failed runs into one-paragraph diagnoses. Bring your own provider — Anthropic, OpenAI, Google, Groq, OpenRouter, or a local Ollama.
→30+ nodes for joins, filters, aggregations, fuzzy matching, pivots, and more. See your data flow in real-time with instant previews at each step.
→Every table stored as Delta Lake with version history, time travel, and merge/upsert support. Track lineage, runs, and artifacts in one place.
→Run flows on intervals or trigger them when catalog tables update. Built into the catalog — not a separate orchestration tool.
→Ingest from Kafka/Redpanda as a canvas node. Read and write to S3, Azure Data Lake, and GCS. Connect to PostgreSQL, MySQL, and more.
→Run arbitrary Python code in isolated Docker containers. Use any library — matplotlib, scikit-learn, or your own — output flows back into the pipeline.
→Export visual flows as Python/Polars scripts. Or build pipelines programmatically with a Polars-compatible API and visualize them on the canvas.
→Use the visual designer for exploration or write code for automation - seamlessly switch between both
import flowfile as ff
df = ff.read_csv("data.csv")
result = df.filter(
ff.col("amount") > 1000
).group_by("region").agg(
ff.col("amount").sum()
)
# Visualize your pipeline
ff.open_graph_in_editor(result.flow_graph)Start rediscovering how we bridge the gap between business users and technical users.
Free, open-source and customizable